Neural Style transfer with Deep Learning
Deep learning is currently a hot topic in Machine learning. The best way to illustrate this is probably through Neural Style Transfer. To get a better understanding of how this technique works I created a couple of images with the original code:

Golden bridge with the style of a snowy scene from Kara no Kyoukai – The Garden of Sinner

Golden bridge with the style of an apocalyptic scene from the same anime
After working on computer vision problems for Atmo I came across Deep Learning, especially Convolutional Neural Networks (CNN). Since I purchased a GTX 970 graphics card for my VR project I had everything needed to start in the world of Deep Learning. After finishing the Deep Learning course at Udacity I decided to take the optional class named Practical Deep Learning in Python and Lua at BME.
There I joined a team that were looking into Neural Style Transfer. We started out with a Tensorflow implementation of the research A Neural Algorithm of Artistic Style. The goal was to get a deep understanding of how neural networks work so we decided to add deep dream and replace the underlying network.
Style Transfer
A very basic explanation of how this works:
The idea is that different layers of the convolutional layers have learned different features in an image. (We don’t use the fully connected layers which are for classification.)
The lower layers close to the input image can only recognize different lines and edges in them while the upper layers have more advanced shapes such as circles, triangles.
The algorithm extracts the style from the lower layers (edges, curves) and the content from the upper layers (shapes). Then it compares them to the input style image and content image and minimizes the differences until it is close enough.
Deep Dream
Deep Dream is achieved by maximizing activations in a specific layer or neuron, for example if an activation represents how likely is it that the image contains a dog, maximizing it will start to form dogs on the picture. Of course the effect can be so little that humans can’t recognise the dogs, only the network can. Octaves solves this problem but the existing network is so different that it would be really hard to implement and it would slow down the process even more.
What we do however is find layers or neurons which are not used in the style and content transfer and maximize the activations there. This way the optimizer will not “fix” deep dream by making style or content more accurate.
With this method we achieved the followings:

Maximizing activations in one layer after 1000 epochs

Maximizing another neuron activation with style transfer
As we thought deep dream creates simple patterns and not something recognisable (e.g. as a dog). Without octaves this is the best we could achieve.
Replacing the network model
We had two networks in mind originally: ResNet and InceptionV3
They have top-5 errors of 5.7% and 5.6% respectively as opposed to the 9.0% of VGG-19. The biggest problem with ResNet is probably its size and thus the backprop time gets even worse. The Inception model is very promising because of the increased accuracy and the required time to run an epoch is about 4 times lower. (These values are based on the CNN-Benchmark and aren’t tested at the time of the writing of this article) .
This might increase the quality a little bit but it is a good way to learn in which layers what kinds of features are represented in the network .
SqueezeNet
My idea was to use SqueezeNet since it has a very small size (4.8MB) compared to the original VGG-19 (510MB) which the default implementation uses. This means a significantly lower number of operations per epoch.
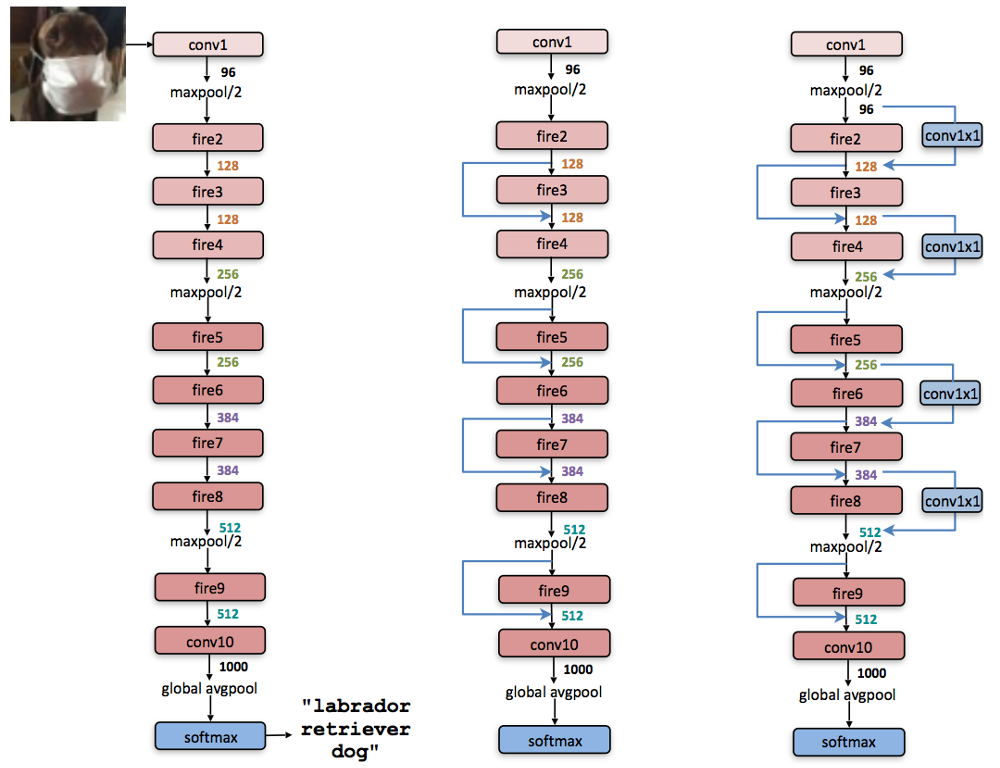
Architecture of SquezeNet
My expectation is that it would fit on mobile phones and run in reasonable time without sacrificing quality too much, and getting better results than the Fast Neural Style. My estimation is that it would run a little faster than ~5/500 => 1% of the time on the GPU. Which for the GTX 970 is about 4 seconds. Of course the GPU is very good at running these operations in parallel and the reduction in the number of neurons wouldn’t utilize this but on a mobile phone this can makes the program runnable in the first place.
I managed to implement the architecture of the network but unfortunately I couldn’t use the pretrained weigths in Tensorflow because it is given in a coffee model. Training a convolutional network this big from scratch is no easy task. It would require hundreds of hours with my resources and there are a lot of ways it can go wrong. I’m leaving this to after my exam period when I have more spare time.
At the end I chose a different path and went with good old Alexnet.

Style Transfer with Alexnet
As you can see the results are far from beautiful. It is true that with this network the epoch finish faster but it needs 10 times more iterations to reach this stage. After all we are sacrificing quality and not gaining any processing time.
Future plans
During the next semester break when I have enough time for the task I’m going to training SqueezeNet with ImageNet and publishing it.
After this project I’m planning to implement kanji learning using CNN for Language Locker. With this feature the users could practice drawing the given kanjis on the lockscreen.
I’ve already found promising data sets: http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html and https://github.com/skishore/makemeahanzi
By combining these two I hope to train an LSTM Neural Network which can recognize even the order of the strokes.